Advanced Test Setup Part 3 - Distributed Systems
This is the third part of my blog series on advanced test setups. The first two parts covered a setup for integration tests and dealing with external APIs.
You do not need to set your tests up the way I described it in the previous posts. And while this entry does build on top of the previous two, the general ideas presented here should be applicable to any setup.
I also wrote before on testing distributed systems in general, which you might want to read first: Testing Distributed Systems. This blog post is an extension of that one, going into more detail on async system communication, and offering some solution ideas.
Distributed Challenges
When designing distributed systems, you need to be aware of the 8 fallacies of distributed computing.
And if you design tests for distributed systems, you should be too! I want to point out a few that I think are especially relevant for testing:
The network is reliable
Two important points here for testing:
- Your tests should not rely on the network being reliable
- You should test how your system behaves when the network is not reliable
When testing, you need to be aware that network calls can fail. For tests that means sometimes you have failing tests that are not bugs of the system per se, but due to network issues.
On the other hand, your tests should simulate those network issues, as they are a reality in production. API mocks and fakes help simulate unexpected server responses. Injecting a sabotaging component into your system can help simulate network failures (to take a page from chaos engineering). For example, you could
- randomly drop messages
- kill the DHCP server
- kill the DNS server
- block certain ports
- ...
Some of the most egregious bugs I had to hunt down in production were due to network issues.
I remember one company that changed its firewall rules a lot, blocking access to upstream services, causing several production incidents.
On another project, there was a bug in a proprietary DHCP server, where IP addresses were wrongly acknowledged when another DHCP server was present in the same network. On that same project we frequently had troubles because some of our clients' networks had terrible internet connectivity.
Things like that happen surprisingly often in production. And the tricky part is, that they only tend to happen when several systems run for a while. Making them hard to spot in testing, when you don't specifically design tests for those scenarios.
Latency is zero
Most distributed systems are asynchronous. In synchronous communication you can block/wait until you get a response - both in production code and in tests. But when going async, your test assertions may suddenly become a lot messier (more on this below).
Another issue with tests is speed. Tests are supposed to be fast (first letter in the FIRST principles). Asynchronous systems often play ping-pong with messages, request from upstream services, etc. This can slow down tests significantly.
You might want to run tests in parallel, but that comes with a different set of challenges (more on this, also, below).
Where to put the test code?
One reason I like mono repos is that it makes obvious where to put test code. When working on distributed systems, you usually work with multiple teams that tend to have their own repos. This raises the question: where do you put the test code?
When testing a single system, you simply stick the tests into the same repository.
But for multi-system tests, you have the choice of either making the tests part of an existing repository, or create one specifically for tests. Either way you will have to deal with a few headaches:
Into an existing repo
If your tests are, for example, E2E tests via the UI, you may be able to put the tests in the same repository as the GUI (if there is only one GUI repo).
Same goes for distributed systems that offer one API gateway, or that use an orchestration architecture with a central orchestrator.
If there is no one repo that offers itself as a natural choice, you will probably put the tests...
Into its own repo
This is what I see more commonly. There is one really annoying problem:
Your tests will be out of sync with the systems they test.
Whether the tests depend on artifacts from the SUTs (e.g. API clients, data models, etc.), or whether they are using the API/GUI directly, you will have regular breakages in your tests.
On a single repository, you would just adjust the tests as part of the code changes to the SUT (for example, in one feature branch). When several repositories are involved, you might need to build a mechanism into your pipelines to automagically (not a typo) merge test branches when the code branch is merged. And only THEN run the tests.
Otherwise, a change to the SUT might break your tests, and good luck finding out why!
I briefly worked with one team that had a separate test repository, and did not update their tests with changes to the SUT. They had two poor saps hunt down false positives in their test runs (almost) full time. Out of a total of 3 test engineers. At this point the ROI of those tests was surely negative...
Dealing with Asynchronicity
In the book "Software Architecture - The Hard Parts" the authors describe eight transaction saga patterns. Without going into detail, I want to note that how you implement your tests depends on the transaction pattern used in the systems' architecture.
For example, if you deal with a distributed system that implements an ACID transaction pattern, then you can simply wait for the transaction to complete before asserting. In eventual consistency patterns, you need to poll for an expected state to be reached before you can assert anything.
Take the following (rough) sequence diagram as an example:
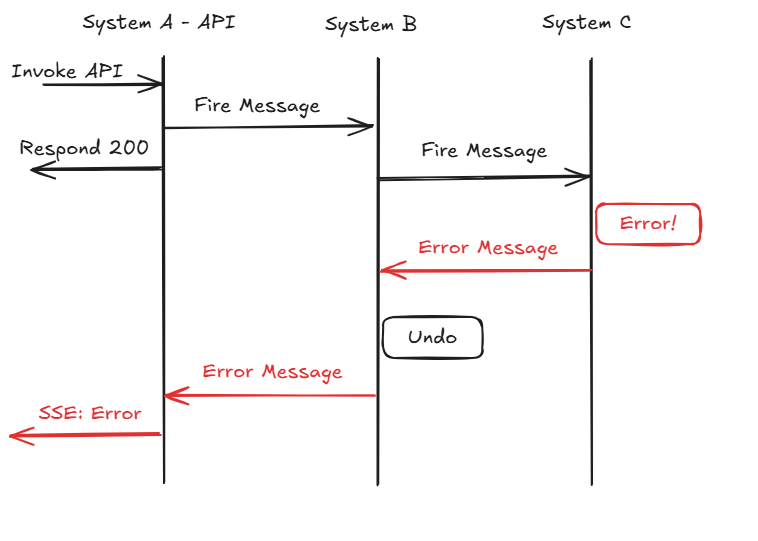
The test invokes the API of System A, which responds 200: OK. Essentially saying: I got your request and will work on it.
Behind the scenes, System A sends a message to System B, which in turn sends a message to System C. System C processes the message and runs into an error (imagine a DB transaction failing due to a unique constraint).
The error is propagated back to System B, which undoes its work and sends a message to System A. System A no longer has an open request to answer to, so it may send out an error message per, for example, Server-Sent Events (SSE) or WebSocket. It might as well do nothing more than just log the error.
Your test still has to fail, though. So you need to design your test to wait for a Server-Sent Event, keep a WebSocket open, poll System A's API, or listen to a Message Queue, etc.
Crucially, your test has to wait for a condition to be met before continuing to assertions.
And here is the tricky part: That condition might never be met!
Remember the 8 fallacies of distributed computing? Networks are unreliable, and that goes for error messages, too. When you look into software architecture for distributed systems, you will find a bunch of literature dealing with those kinds of challenges.
For further reading, I recommend the books "Designing Data-Intensive Applications" by Martin Kleppmann and "Enterprise Integration Patterns".
Your tests will need to either poll for a condition to be met, or wait for a message/event to arrive. Either way, you will need to implement a timeout, after which the test fails. This is important, as otherwise your tests might hang forever!
Parallel Test Runs
When you run tests in parallel, you need to be aware that your tests might interfere with each other. I previously wrote about this in a post on testing distributed systems.
I don't want to repeat myself, so just a few relevant bullet points here:
- Isolate tests by using unique data and, if possible, "silos" (separate aggregates, test customers/tenants, etc.)
- Be careful to only clean up data that belongs to the test
Driving multiple Systems
Usually, when testing multiple systems, you will want to interact with more than one of those systems.
If there is a central point of entry (API Gateway, Orchestrator, etc.), you will want to start tests this way. But you may still need to read data from other systems to assert state or log errors for further analysis.
I tend to write a test client library for each system I want to interact with. I call these libraries my "Drivers", as they "drive" the system under test.
(I confess to have stolen this idea from Selenium WebDrivers.)
Keeping these drivers in separate modules/classes has a few advantages:
- You encapsulate the logic of interacting with the system, hiding implementation details (e.g. HTTP calls, authentication, etc.) away from your test code.
- You may write the drivers as part of the SUT's repository (like a client library) and import those in your tests; this has the additional benefit that breaking changes to the SUT will make the test code uncompilable, forcing you to fix the tests.
- It is easier to create a DSL (Domain-Specific Language) for each system, making the test code more readable.
My drivers usually do not only implement the API of the system, but also helper methods to set up test data, clean up after tests, etc. and I like to bundle with the API code
- data access code to the SUT's database (as needed)
- event listeners for relevant message queues, SSE, WebSockets, etc. from the target SUT
- guard assertions to verify that the SUT is in a valid state before continuing tests
Black Boxes
Most distributed systems at some point interact with external systems - SaaS products, third-party APIs, etc. Those do not always offer good integration points for tests, and sometimes there is no test environment at all.
As I wrote about before, you will want to treat those systems either as black boxes or mock/fake them.
Conclusion
Distributed, asynchronous systems are hard to test.
Depending on the architecture, technology, and unique properties of the system you are working with, you will find a lot of additional challenges not described here.
I presented here my approach of using test drivers, polling, and timeout mechanisms to deal with such systems in general.
If you have any questions, suggestions, or want to share your own experiences, please reach out to me. Contact information can be found on this website.
And if you need help setting up tests for your distributed systems, please get in touch! I am always happy to help.